Take your customer experience to the next level
Instantly uncover, understand, and quantify users’ friction points to prioritize initiatives that will increase customer satisfaction and engagement while reducing contact rate and churn
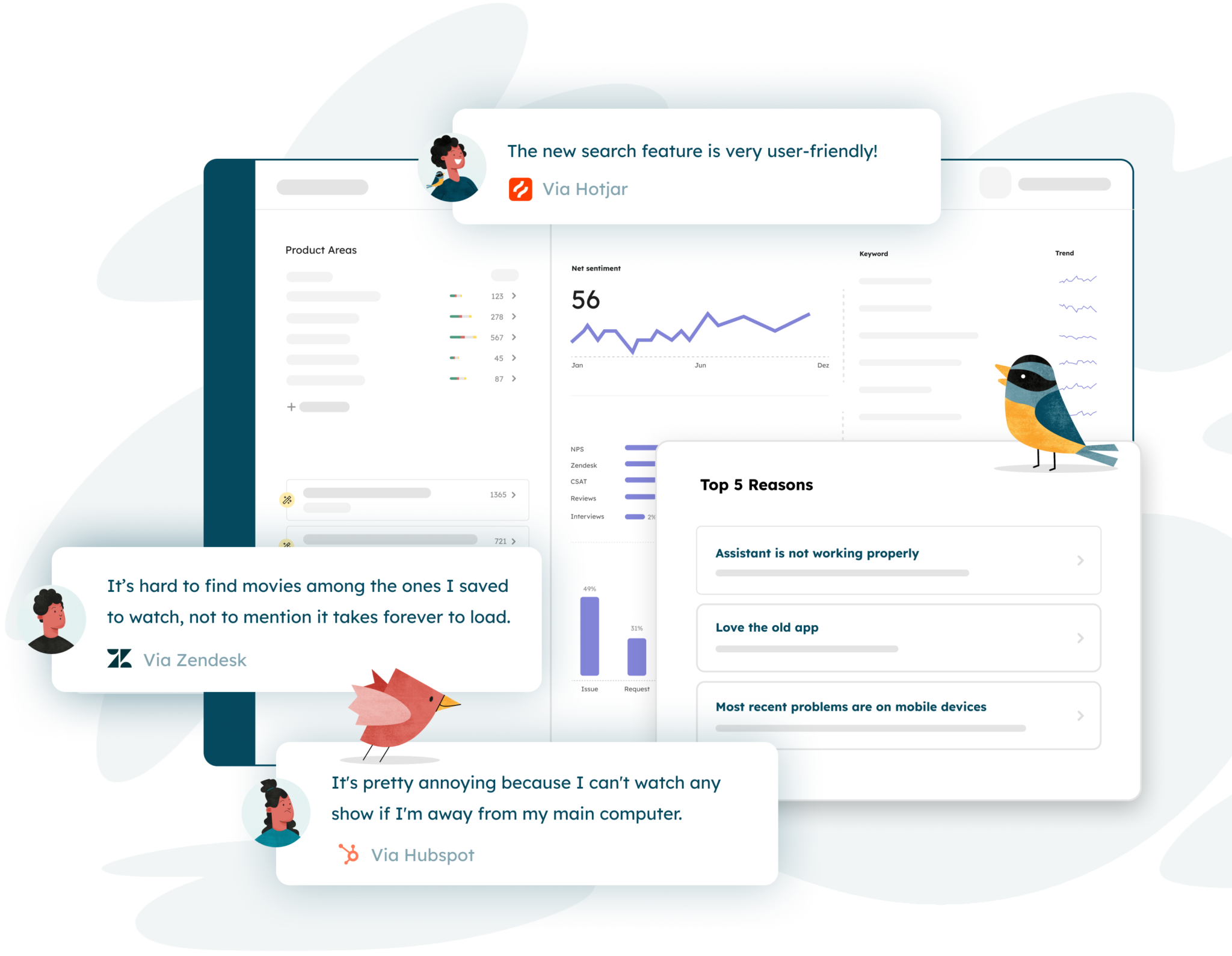
Instantly uncover, understand, and quantify users’ friction points to prioritize initiatives that will increase customer satisfaction and engagement while reducing contact rate and churn
Centralize customer feedback from internal and external sources to uncover and quantify customer needs and pain points, generating insights that will lead to lower churn, better retention, and lower contact rate


Build a single source of customer feedback, profile, and behavior to enable easy access and exploration of contextualized user feedback

Automatically report key metrics – like NPS, contact rate, and net sentiment – by product, feature, journey, or customer segment and across all feedback sources

Uncover, validate, track, and quantify the impact of existing problems or requests in seconds with AI-powered feedback analysis
From Customer Experience to Product, Birdie empowers customer-centric teams to effortlessly transform feedback into actionable insights about what to prioritize to improve product experience

Elevate the value of your CX programs with automated real-time VoC reporting, 100% coverage of feedback across sources, and more contextualized and segmented insights

Enhance your product intuition and customer empathy, accelerate product discovery, and simplify roadmap prioritization by using contextualized feedback as evidence

Establish a single source of truth for feedback with a customer-centric product prioritization process that will fuel your product organization’s growth


















![[Masterclass] Scaling feedback loops across the PDLC](https://birdie.ai/wp-content/uploads/2023/01/Blog-Posts-6-300x225.png)
